

NoSQL Databases: A Detailed
Description

Over the years the total data in world has tripled and the growth continues to be rapid. Today, this overflowing data needs to be accepted and the adaptation of new database technology has become a new challenge. This challenge has led to the birth of NoSQL. The term Not Only SQL is nothing but so called Big Data Technology which is growing widely day by day
NoSQL ?
The 2000’s has led to the emergence of NoSQL due to the drastic decrease in the cost of storage, leading the developers to store data in a format other than relational tables. The Not Only SQL database doesn’t split data between tables, therefore making it simpler and easier. In short NoSQL works on storing data in a non-tabular format. It is also an approach to database design that can accommodate a wide variety of data models, including key-value, document, columnar and graph formats.
Why NoSQL ?
The limitations of traditional relational scale-up architecture involving the usage of large computers with high memory is ruled out by NoSQL. The databases of NoSQL are created in Internet and cloud computing eras that made it possible to more easily implement a scale-out architecture where scalability is achieved.Few advantages of NoSQL database are as follows:
1. More Scalable than traditional database
2. High Performance
3. Faster than traditional database
4. Worked with rapidly changing
datatypes-Structured, Non-Structured, unstructured, Polymorphic data.
Types of NoSQL Databases:
NoSQL databases can broadly be categorized in four types.

Key-Value databases :
A key-value database is a data storage paradigm designed for storing, retrieving, and managing associative arrays, a data structure more commonly known today as a dictionary or hash table.
In
key-value databases, updates to the value for a single key are usually atomic.
Furthermore, many key-value databases allow for transactions which use multiple
keys. Also, values have limited structure.
The advantages about key-value databases are:
- Key-value databases are generally easier to run in a distributed fashion.
- Queries and updates usually very fast.
- Any type of data in any structure can be stored as a value.
However, the disadvantages about key-value databases are:
- Very simple queries (usually just get a value given a key, sometimes a range).
- No referential integrity.
- Limited transactional capabilities.
Some of the popular key-value databases are Riak, Redis Memcached and its flavors, Berkeley DB, upscaledb Amazon DynamoDB, Project Voldemort and Couchbase.
Below is the example of how to insert data in Redis:

Document databases :
The
document database stores and retrieves documents, which can be XML, JSON, BSON,
and so on. These documents are self-describing, hierarchical tree data
structures which can consist of maps, collections, and scalar values. The
documents stored are similar to each other but do not have to be exactly the
same.
Some of the popular document databases we have seen are MongoDB,CouchDB,Terrastore,OrientDB RavenDB and Lotus Notes that uses document storage.
The most popular document database is MongoDB(from “humongous”), which is open-source and stores data in flexible, JSON-like documents,meaning fields can vary from document to document and data structure can be changed over time. The MongoDB hierarchy starts out with the database, then a collection, then a document.
Below is the example of how to create a new collection or view in MongoDB

Column family stores:
These databases store data in column families as rows that have many columns associated with a row key. Column families are groups of related data that is often accessed together. When a column consists of a map of columns, we have a super column. A super column consists of a name and a value.
Cassandra is one of the popular column-family databases. Cassandra can be described as fast and easily scalable with write operations spread across the cluster. The cluster does not have a master node, so any read and write can be handled by any node in the cluster.
Other examples include HBase, HyperTable and Amazon DynamoDB
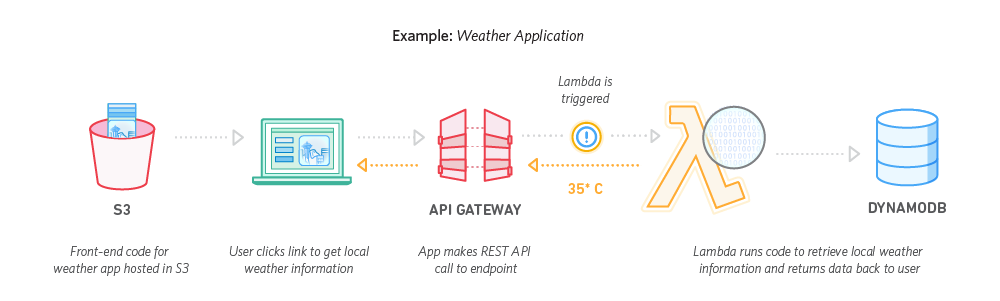
Graph Databases:
Graph databases allow you to store entities and relationships between these entities. While entities are also known as nodes, which have properties, relations are known as edges that can have properties. Edges have directional significance, whereas nodes are organized by relationships which allow you to find interesting patterns between the nodes. The organization of the graph lets the data to be stored once and then interpreted in different ways based on relationships.
In graph databases, traversing the joins or relationships is very fast. The relationship between nodes is not calculated at query time but is actually persisted as a relationship. Traversing persisted relationships is faster than calculating them for every query.
There are many graph databases available, such as Neo4J, Infinite Graph, OrientDB, or FlockDB

Conclusion:
The reason why NoSQL Databases have been so popular is mainly because, when a relational database grows out of one server, it is no longer that easy to use. In other words, they don’t scale out very well in a distributed system.
We are entering an era of polyglot persistence, a technique that uses different data storage technologies to handle varying data storage needs. Polyglot persistence can apply across an enterprise or within a single application. This flexible system of storing data and its ease to access is the reason why NOSQL databases are becoming so popular right now.


0 Comments